
Technical SEO is the process of optimizing a website’s infrastructure so search engines can efficiently crawl, index, and rank its pages, covering everything from site speed and mobile usability to structured data, security, and duplicate content management. Without a technically sound foundation, even the strongest content and most authoritative backlinks will underperform in search results. For business owners, marketers, and anyone responsible for organic visibility, understanding technical SEO is the starting point for every other SEO investment.
Ignoring technical SEO means your pages may never reach Google’s index, load too slowly to retain visitors, or send conflicting signals that prevent rankings from improving regardless of content quality.
This guide covers how search engines crawl and index websites, site architecture, XML sitemaps, Core Web Vitals, mobile-first indexing, HTTPS, structured data, duplicate content, technical audits, and how to get started.

How Search Engines Crawl and Index Your Website
Before any page can appear in Google’s search results, two things must happen: the page must be crawled, and it must be indexed. These are distinct processes, and both must work correctly for your content to have any chance of ranking.
Crawling is the discovery process. Search engines deploy automated programs called spiders or bots — Google’s is called Googlebot — that systematically follow links across the web to find and scan web pages. Googlebot reads the content of each page it visits, follows the links it finds there, and adds new URLs to its queue for future crawling. Crawling is how Google becomes aware that your page exists.
Indexing is what happens after crawling. Once Googlebot has scanned a page, it processes the content and stores a version of it in Google’s index — a massive database of web pages that Google draws from when generating search results. A page that has been crawled but not indexed will never appear in search results, regardless of how well-optimized it is.
What Is Crawling and How Does Googlebot Work?
Googlebot does not crawl every page on the internet with equal frequency or depth. It operates within a crawl budget — the number of pages it will crawl on a given site within a given timeframe. Sites with strong technical foundations, fast load times, and clean internal linking structures tend to have their important pages crawled more frequently. Sites with crawl errors, redirect chains, or bloated URL structures waste crawl budget on low-value pages, leaving important content undiscovered.
What Is Indexing and How Does It Differ from Crawling?
Indexing is not automatic. Google may crawl a page and choose not to index it if the content is thin, duplicated, blocked by a noindex directive, or otherwise deemed low-quality. The Google Search Console Coverage report is the primary tool for identifying which pages on your site have been indexed and which have been excluded — and why.
Crawling and indexing are the gateway processes that determine whether your pages ever reach Google’s search results — our guide to crawlability and indexation fundamentals, covers how to diagnose crawl errors, manage crawl budget effectively, and ensure every important page on your site is discoverable and indexed correctly.
Site Architecture and URL Structure
The way your website is organized has a direct impact on how efficiently search engines can crawl it and how effectively link equity — the ranking power passed through links — flows to your most important pages. Site architecture is not just a design decision; it is a technical SEO decision with measurable consequences for organic visibility.
A well-designed site architecture follows a flat hierarchy — meaning any page on the site can be reached within three to four clicks from the homepage. This keeps important pages close to the root of the domain, where Googlebot is most likely to discover and prioritize them. A deep hierarchy, by contrast, buries pages five, six, or seven levels down in the folder structure, making them harder to crawl and reducing the link equity they receive.
How Flat vs. Deep Site Architecture Affects SEO
In a flat architecture, link equity from the homepage flows efficiently to category pages, which pass it to individual content pages. In a deep architecture, that equity is diluted across too many levels before it reaches the pages that need it most. For businesses with large websites — e-commerce stores, service directories, or content-heavy blogs — this distinction can meaningfully affect which pages rank and which remain invisible.
URL Best Practices for Search Engines
URLs should be short, descriptive, and structured to reflect the site’s hierarchy. Best practices include using lowercase letters, hyphens to separate words, and avoiding unnecessary parameters, session IDs, or dynamic strings that create duplicate URL variants. A clean URL structure also improves user clarity — a visitor reading the URL should be able to understand what the page covers before clicking.
A well-structured site is one of the highest-leverage technical SEO investments you can make, our guide to site architecture for SEO walks through how to design a crawlable hierarchy, implement internal linking correctly, and structure URLs in a way that distributes authority to your most important pages.
XML Sitemaps and Robots.txt
Two files play a central role in how search engines navigate your website: the XML sitemap and the robots.txt file. They serve complementary purposes — one tells crawlers where to go, and the other tells them where not to go.
What an XML Sitemap Does and When You Need One
An XML sitemap is a file that lists all the important URLs on your website, helping search engines discover and prioritize which pages to crawl and index. Rather than relying entirely on link discovery — where Googlebot follows links from page to page — a sitemap provides a direct inventory of your site’s content. This is especially valuable for large sites, newly launched sites with few inbound links, or sites with pages that are not well-connected through internal linking.
Sitemaps can be submitted directly to Google through Google Search Console, giving you a direct channel to communicate which pages you consider most important. A sitemap does not guarantee indexation — Google still evaluates each URL on its own merits — but it significantly improves the likelihood that important pages are discovered promptly.
How Robots.txt Controls Crawler Access
The robots.txt file is a plain text file stored at the root of your domain that instructs search engine crawlers which sections of your site they are and are not permitted to access. Using disallow directives, you can prevent Googlebot from crawling admin pages, staging environments, duplicate content sections, or any other areas that should not appear in search results.
It is important to understand that robots.txt controls crawling, not indexing. A page blocked by robots.txt can still be indexed if other sites link to it — to prevent indexation, a noindex directive on the page itself is required.
Getting your sitemap and robots.txt right is one of the first technical SEO tasks any site should complete, our detailed guide to XML sitemaps and robots.txt setup covers how to generate, configure, and submit both files correctly so search engines can access your content without restriction or confusion.

Page Speed and Core Web Vitals
Page speed has been a Google ranking factor since 2010, but the introduction of Core Web Vitals in 2021 transformed how performance is measured and weighted in search rankings. Rather than relying on a single speed score, Google now evaluates three specific dimensions of real-world user experience — and uses them directly in its ranking algorithm.
Core Web Vitals are three Google-defined metrics that measure how real users experience a webpage’s loading performance, interactivity, and visual stability. According to Google’s developer documentation, the three metrics are:
- Largest Contentful Paint (LCP): Measures how long it takes for the largest visible content element — typically a hero image or headline — to load. A good LCP score is under 2.5 seconds.
- Interaction to Next Paint (INP): Measures how quickly a page responds to user interactions such as clicks or taps. A good INP score is under 200 milliseconds.
- Cumulative Layout Shift (CLS): Measures how much the page layout shifts unexpectedly during loading. A good CLS score is under 0.1.
What Are Core Web Vitals and Why Do They Affect Rankings?
Google uses Core Web Vitals as a ranking signal because they reflect the quality of the experience users actually have on a page — not just how fast a server responds. A page that loads quickly but shifts its layout unexpectedly, or one that appears fast but takes seconds to respond to a tap, creates a poor user experience that Google’s algorithm now penalizes.
Research from Google has shown that sites meeting Core Web Vitals thresholds see measurably lower bounce rates and higher session durations — outcomes that reinforce the connection between technical performance and business results.
Key Factors That Slow Down a Website
The most common causes of poor Core Web Vitals scores include unoptimized images, render-blocking JavaScript and CSS, slow server response times (TTFB), third-party scripts that delay interactivity, and unstable ad or embed placements that cause layout shifts. Each of these has specific technical remedies — but diagnosing which factors are affecting your specific site requires measurement tools like Google PageSpeed Insights or Google Search Console’s Core Web Vitals report.
Core Web Vitals are now a confirmed Google ranking factor, making performance optimization a non-negotiable part of any technical SEO strategy, our guide to Core Web Vitals optimization breaks down exactly how LCP, INP, and CLS are measured, what scores you need to achieve, and the specific technical fixes that move the needle on each metric.
Mobile-First Indexing and Responsive Design
Google completed its transition to mobile-first indexing for all websites in 2023, meaning it now uses the mobile version of your website — not the desktop version — as the primary basis for crawling, indexing, and ranking. If your mobile site has less content, slower load times, or a different structure than your desktop site, your rankings will reflect the mobile version’s quality, regardless of how strong your desktop experience is.
This shift reflects the reality of how people search. Statcounter data consistently shows that mobile devices account for over 55% of global web traffic, making mobile performance a majority-use-case requirement, not an edge case.
What Mobile-First Indexing Means for Your Site
For most modern websites built on responsive design frameworks — where a single codebase adapts its layout to different screen sizes — mobile-first indexing requires no structural changes. The same content, the same URLs, and the same metadata are served to both mobile and desktop users, which is exactly what Google recommends.
Problems arise when sites maintain separate mobile and desktop versions (m-dot sites), when mobile pages have stripped-down content compared to desktop, or when mobile pages load significantly slower due to unoptimized assets. In these cases, the mobile version’s weaknesses directly translate into ranking disadvantages.
Since Google now indexes and ranks websites based on their mobile version first, ensuring your site performs correctly on smartphones is no longer optional, our guide to mobile SEO best practices covers responsive design requirements, mobile usability testing, and the specific technical configurations that prevent your mobile site from undermining your rankings.
HTTPS, Site Security, and Technical Trust Signals
HTTPS (Hypertext Transfer Protocol Secure) is the encrypted version of HTTP, the protocol that governs how data is transferred between a user’s browser and a web server. Google confirmed HTTPS as a ranking signal in 2014, and since then, the presence of a valid SSL/TLS certificate has become a baseline technical requirement for any site that wants to compete in organic search.
The SEO implications of HTTPS extend beyond the ranking signal itself. Browsers including Chrome display a “Not Secure” warning for any site still running on HTTP — a warning that appears prominently in the address bar and has been shown to increase bounce rates as users lose confidence in the site’s legitimacy. For business websites, this trust erosion translates directly into lost leads and reduced conversion rates.
Why HTTPS Is a Google Ranking Signal
Google’s rationale for using HTTPS as a ranking signal is rooted in user safety. Encrypted connections protect the data users share with a website — including form submissions, login credentials, and payment information — from interception. By rewarding HTTPS sites in rankings, Google creates an incentive structure that pushes the web toward greater security as a default.
For sites that have not yet migrated to HTTPS, the process involves obtaining an SSL certificate (available free through providers like Let’s Encrypt), configuring the server to serve all pages over HTTPS, and implementing 301 redirects from all HTTP URLs to their HTTPS equivalents. Each step must be executed correctly to avoid ranking disruptions during the migration.
Switching from HTTP to HTTPS is one of the most straightforward technical SEO improvements available, but it requires careful execution to avoid ranking drops, our guide to HTTPS migration for SEO walks through the complete migration process, how to handle redirects correctly, and how to resolve mixed content issues that can undermine your security signals after migration.
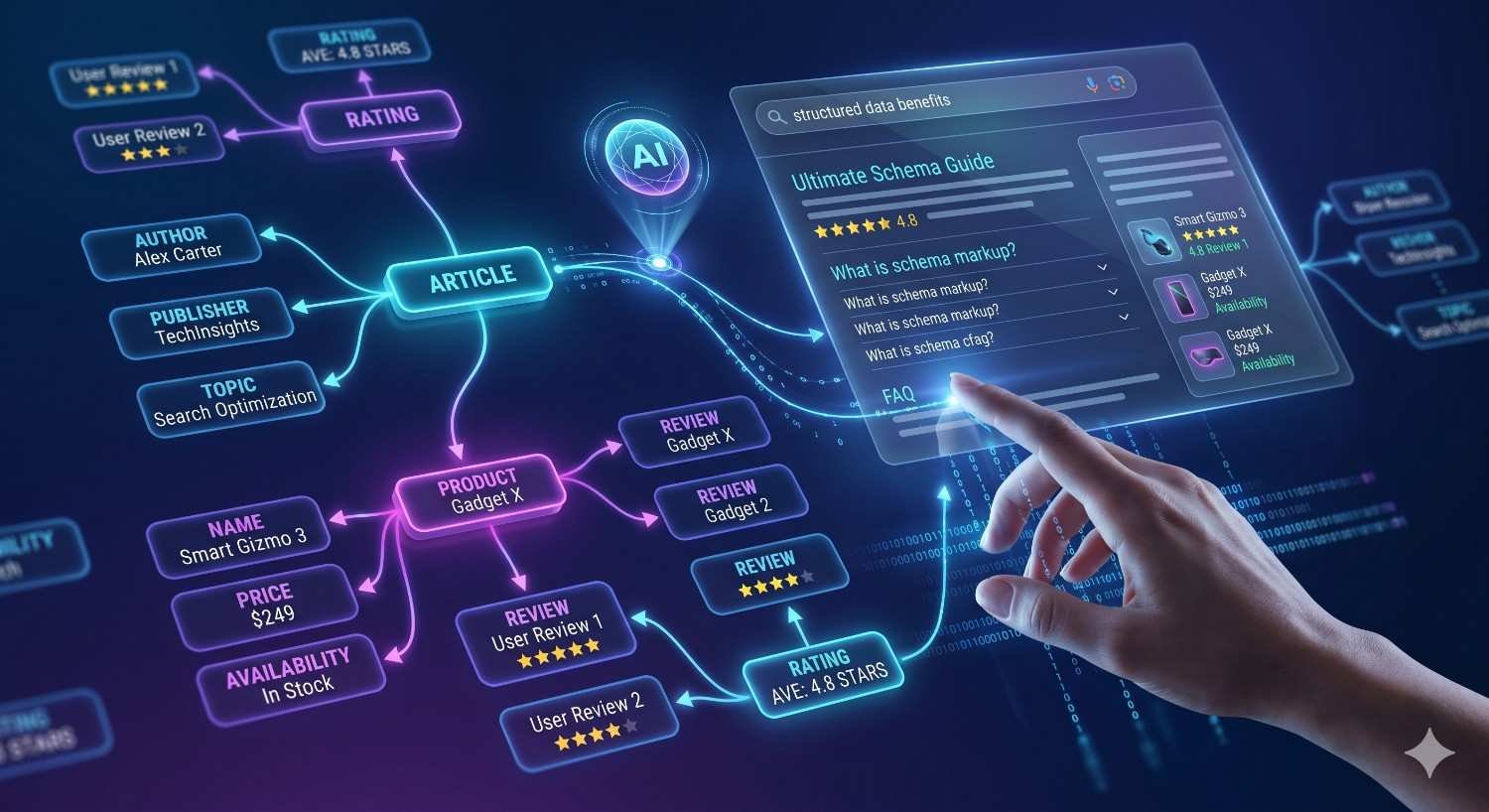
Structured Data and Schema Markup
Structured data is code added to a webpage that helps search engines understand the content’s meaning and context — not just its words, but what those words represent. Using a standardized vocabulary from Schema.org, structured data communicates to Google whether a page contains a product, a recipe, an FAQ, a local business, an event, or any of hundreds of other content types.
When Google can confidently interpret what a page is about, it can display that information in enriched formats directly in search results — known as rich results or rich snippets. These enhanced listings can include star ratings, pricing, availability, FAQ dropdowns, and other visual elements that make a result stand out from standard blue-link listings.
What Schema Markup Does for Search Visibility
The primary business value of schema markup is its impact on click-through rates. A result with star ratings, a price range, or an FAQ expansion visible directly in the SERP attracts significantly more attention than a plain text listing. Research from Milestone Inc. found that pages with structured data see up to 30% higher click-through rates compared to equivalent pages without it.
Schema markup does not directly improve a page’s ranking position — it improves the visibility and appeal of the listing at whatever position the page already holds. For competitive queries where multiple results occupy similar positions, rich results can be the differentiating factor that drives clicks.
Which Schema Types Matter Most for Business Websites
The most impactful schema types for business websites include:
- LocalBusiness schema — communicates business name, address, phone number, hours, and category to Google’s local knowledge graph
- FAQ schema — enables FAQ dropdowns to appear directly in search results, expanding the visual footprint of a listing
- Product schema — displays pricing, availability, and review ratings for e-commerce pages
- Organization schema — establishes brand identity, logo, and contact information at the entity level
- Article or BlogPosting schema — helps Google understand content type and publication date for informational pages
Schema markup is one of the most underused technical SEO tools available to business websites, yet it can directly increase click-through rates by unlocking rich results in Google Search, our structured data implementation guide covers the most valuable schema types for business sites, how to implement them correctly using JSON-LD, and how to test and validate your markup before publishing.
Duplicate Content, Canonical Tags, and Crawl Budget
Duplicate content occurs when the same or substantially similar content appears at multiple URLs on a website. This is more common than most site owners realize — it can be caused by URL parameters (such as session IDs or tracking codes), HTTP vs. HTTPS versions of the same page, www vs. non-www variants, trailing slash vs. no trailing slash URLs, or printer-friendly page versions. When search engines encounter multiple URLs with identical content, they face a choice: which version should be indexed and ranked?
Without clear guidance, Google may index the wrong version, split ranking signals across multiple URLs, or choose to index none of them — all outcomes that reduce organic visibility.
What Causes Duplicate Content and Why It Hurts Rankings
The core problem with duplicate content is signal dilution. If three URLs contain the same content, any backlinks pointing to those pages are split across three destinations rather than consolidated into one. The page that should rank receives only a fraction of the authority it would have if all signals pointed to a single canonical URL. For sites with large numbers of duplicate URLs, this dilution can meaningfully suppress rankings across entire sections of the site.
How Canonical Tags and Crawl Budget Work Together
The canonical tag (rel=canonical) is an HTML element placed in the head of a page that tells search engines which URL is the preferred, authoritative version of that content. By pointing all duplicate variants to the canonical URL, you consolidate ranking signals and prevent indexation conflicts.
Canonical tags also interact with crawl budget. Every time Googlebot crawls a duplicate URL, it spends crawl budget on a page that adds no indexation value. For large sites with thousands of duplicate URLs, this waste can mean that important new content takes longer to be discovered and indexed. Resolving duplicate content through canonical tags and 301 redirects frees crawl budget for the pages that matter.
Duplicate content is one of the most common technical SEO issues found during site audits, and resolving it correctly requires understanding both canonical tags and how crawl budget is being spent, our guide to duplicate content and canonicalization explains how to identify duplicate URLs, implement canonical tags correctly, and consolidate crawl budget toward your most valuable pages.
Technical SEO Audits — What They Are and What They Find
A technical SEO audit is a systematic examination of a website’s technical infrastructure to identify issues that are preventing pages from being crawled, indexed, or ranked as effectively as they should be. It is the diagnostic process that connects all the components covered in this guide — crawlability, site architecture, page speed, mobile usability, security, structured data, and duplicate content — into a single, prioritized action plan.
Technical audits are not a one-time exercise. Search engines update their algorithms, websites accumulate technical debt over time, and new content or structural changes can introduce issues that were not present during the last audit. A 2023 study by Semrush found that over 65% of websites have critical technical SEO issues that are actively suppressing their organic performance — issues that a structured audit would surface and prioritize.
What a Technical SEO Audit Covers
A comprehensive technical SEO audit examines the following categories:
- Crawlability: Are all important pages accessible to Googlebot? Are there crawl errors, blocked resources, or redirect chains wasting crawl budget?
- Indexation: Which pages are indexed? Which are excluded, and why? Are there noindex directives applied incorrectly?
- Page speed and Core Web Vitals: Do pages meet Google’s performance thresholds? What specific elements are causing delays?
- Mobile usability: Does the site pass Google’s mobile-friendly test? Are there viewport or touch target issues?
- HTTPS and security: Is the SSL certificate valid? Are there mixed content warnings or insecure resources?
- Structured data: Is schema markup present, valid, and generating rich results?
- Duplicate content: Are there duplicate URLs, thin content pages, or canonicalization conflicts?
- Internal linking: Are there orphan pages, broken internal links, or redirect chains in the internal link structure?
- Broken links and 404 errors: Are there external links pointing to pages that no longer exist?
How Often Should You Run a Technical SEO Audit?
For most business websites, a full technical SEO audit should be conducted at minimum once per year, with lighter monthly monitoring using tools like Google Search Console to catch emerging issues between full audits. Sites that publish content frequently, undergo regular development changes, or operate in competitive verticals benefit from quarterly audits. Any major site migration — changing domains, switching CMS platforms, or restructuring URLs — should trigger an immediate pre- and post-migration audit.
Running a technical SEO audit is the most reliable way to identify exactly which issues are holding your site back from its ranking potential — our guide to the complete technical SEO audit process walks through every audit category, the tools used at each stage, and how to prioritize fixes by their impact on organic visibility.
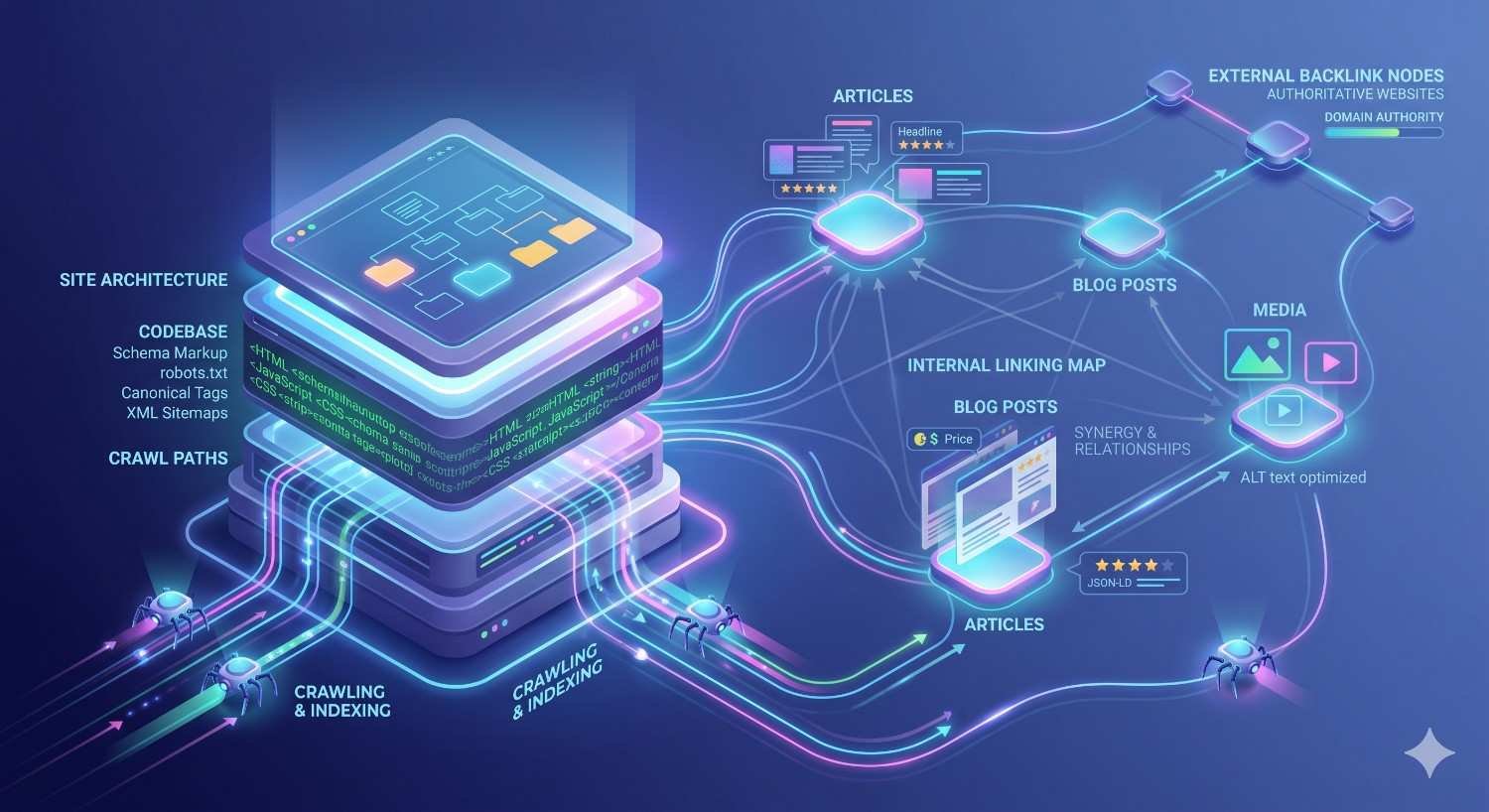
How Technical SEO Connects to Content and Link Building
Technical SEO does not operate in isolation. It is the foundation layer of a three-part system — alongside content and link building — that together determines how well a website performs in organic search. Understanding how these three components interact is essential for setting realistic expectations and making informed SEO investment decisions.
Think of it this way: technical SEO makes your site accessible and interpretable to search engines. Content gives search engines something worth ranking. Link building signals to search engines that other authoritative sources consider your content worth referencing. Each layer depends on the others. Strong content on a technically broken site will underperform because search engines cannot efficiently crawl or index it. A technically perfect site with no content depth will have nothing to rank for. And a site with excellent content and technical health but no external authority signals will struggle to compete against established domains in competitive markets.
Why Technical SEO Is the Foundation, Not the Finish Line
The most common mistake businesses make when approaching SEO is treating technical fixes as the end goal rather than the starting point. Resolving crawl errors, improving Core Web Vitals, and implementing schema markup are necessary conditions for organic visibility — but they are not sufficient on their own. Once the technical foundation is solid, the focus shifts to content quality, topical authority, and the acquisition of relevant backlinks from credible sources.
This is why a structured SEO strategy sequences technical work first: it ensures that every subsequent investment in content and link building lands on a site that search engines can fully access, understand, and evaluate.
For businesses that need all three pillars, technical SEO, content, and authority building — working together as a coordinated system, partnering with an experienced team that manages a full-service SEO strategy can compress the learning curve and accelerate the path to measurable organic growth.
How to Get Started with Technical SEO (Without Getting Overwhelmed)
Technical SEO has many components, but it has a clear starting sequence. The goal at the beginning is not to fix everything at once — it is to identify the issues with the highest impact on crawlability and indexation, resolve those first, and build from there.
Step 1: Set up Google Search Console. This free tool from Google provides direct visibility into how Googlebot sees your site — including which pages are indexed, which have errors, which have Core Web Vitals issues, and which have structured data problems. It is the single most important technical SEO tool available and costs nothing to use.
Step 2: Run a site audit. Use a crawl-based audit tool — Screaming Frog, Semrush, or Ahrefs are the most widely used — to generate a full inventory of technical issues across your site. The audit will surface broken links, redirect chains, missing meta tags, duplicate content, slow pages, and dozens of other issues in a single report.
Step 3: Prioritize by impact. Not all technical issues carry equal weight. Prioritize in this order: crawl errors and indexation blocks first (pages that cannot be found cannot rank), then page speed and Core Web Vitals (performance affects rankings and user experience simultaneously), then structured data and schema (enhances visibility without affecting rankings directly), then duplicate content and canonicalization (prevents signal dilution over time).
Prioritizing Technical SEO Fixes by Impact
| Priority | Issue Type | Why It Matters First |
| Critical | Crawl errors, noindex on important pages, blocked resources | Pages that cannot be crawled or indexed cannot rank — period |
| High | Core Web Vitals failures, slow page speed | Direct ranking signal; affects user experience and bounce rates |
| High | HTTPS not implemented | Ranking signal + trust signal; browser warnings increase bounce rates |
| Medium | Duplicate content, missing canonical tags | Dilutes ranking signals; wastes crawl budget over time |
| Medium | Missing or invalid structured data | Missed rich result opportunities; no direct ranking impact |
| Lower | Minor redirect chains, thin content pages | Crawl budget inefficiency; lower urgency than critical issues |
For agencies and businesses that need technical SEO executed at scale without building an in-house team, white label SEO services provide a fully managed technical SEO delivery model, covering audits, implementation, and ongoing performance monitoring under your brand or directly for your clients.
Conclusion
Technical SEO encompasses the infrastructure-level decisions — crawlability, site architecture, page speed, mobile usability, security, structured data, and duplicate content management — that determine whether search engines can access, understand, and rank your website’s content effectively.
Mastering these components does not require becoming a developer. It requires understanding what each element does, why it matters, and how to prioritize fixes in a sequence that builds a solid foundation for every other SEO investment you make.
At White Label SEO Service, we help businesses and agencies build that foundation correctly — from technical audits and implementation to ongoing performance monitoring that keeps organic visibility growing over time.
Frequently Asked Questions
What is technical SEO in simple terms?
Technical SEO is the process of optimizing a website’s infrastructure so search engines can efficiently crawl, index, and rank its pages. It covers site speed, mobile usability, security, structured data, and duplicate content — the behind-the-scenes factors that determine whether your content can be found in search results.
How is technical SEO different from on-page SEO?
Technical SEO focuses on a website’s infrastructure — crawlability, speed, security, and indexation. On-page SEO focuses on the content of individual pages — keyword usage, headings, meta tags, and internal linking. Both are necessary; technical SEO ensures pages can be found, while on-page SEO ensures they are relevant to the right queries.
Does technical SEO directly affect Google rankings?
Yes — several technical SEO factors are confirmed Google ranking signals, including page speed, Core Web Vitals, HTTPS, and mobile usability. Others, like structured data, do not directly affect rankings but improve click-through rates by enabling rich results. Crawlability and indexation are prerequisites for ranking at all.
How long does it take to see results from technical SEO improvements?
Results from technical SEO fixes typically appear within four to twelve weeks, depending on how frequently Google recrawls your site and the severity of the issues resolved. Critical fixes — such as resolving indexation blocks or improving Core Web Vitals — tend to show measurable impact faster than lower-priority improvements like structured data implementation.
Can I do technical SEO myself, or do I need an agency?
Many foundational technical SEO tasks — setting up Google Search Console, submitting a sitemap, checking for crawl errors — can be done without technical expertise. More complex work, such as resolving JavaScript rendering issues, managing large-scale duplicate content, or executing a site migration, typically requires developer involvement or an experienced SEO team.
What tools do I need for technical SEO?
The essential starting toolkit includes Google Search Console (free, direct data from Google), Google PageSpeed Insights (free, Core Web Vitals measurement), and a crawl-based audit tool such as Screaming Frog, Semrush, or Ahrefs. For most business websites, these three tool categories cover the majority of technical SEO monitoring and diagnostic needs.
How often should I review my site’s technical SEO?
Most business websites benefit from a full technical SEO audit at least once per year, with monthly monitoring through Google Search Console to catch emerging issues between audits. Sites that publish content frequently, undergo regular development changes, or have recently migrated to a new platform should audit more frequently — quarterly at minimum.


